Build your scalable GTM automation systems: From 100 to 10K leads - no breaking
Build your scalable GTM automation systems: From 100 to 10K leads - no breaking
Everything’s humming. Your sales reps are on top of every lead, DM, OOO reply. You’re hitting numbers, feeling cocky, maybe even thinking you’ve cracked the code.
Then you scale and everything goes to sh*t.
300 ICP-fit leads sit cold in Clay for a week; your webhook never fired. Your dashboard says “all green” while your pipeline bleeds qualified prospects. The SDR manager asks why numbers dropped, and you’re digging through logs at 11 PM trying to figure out where the system broke.
Been there, done that.
Here’s the thing: automation only works if your manual systems are airtight.
If your handoffs, data fields, or exits are sloppy, scaling won’t fix them; it will amplify them, and they’ll break louder.
Most teams build automation for hundreds of leads/month, then try to push thousands through the same duct-taped setup without catching bottlenecks.
The only operators who actually survive fix their manual ops first and run the most reliable systems, not expensive stacks. They built automation that doesn't break when volume hits. Aka:
- Clean signal catalogs with clear ownership.
- Data contracts that enforce themselves.
- Exit logic that actually fires when someone books a call.
- Observability that surfaces failures before they cost pipeline.
This isn’t another “Go-To-Market best practices” post. It's a playbook with 4 modular systems you can implement as you start to scale, plus the foundational assets you need to reach 10x volume without losing your sanity.
Why GTM automation systems fail (and how to fix them)
Most go-to-market strategies fail from bad orchestration between teams and tools, not bad planning. When there are cracks in ops before automation, scaling just makes the damage louder and harder to ignore.
These three things break first:
1. Signal handoffs fail: Your SDR manager asks, "Why aren't we hitting numbers?" You check Clay. 200 ICP-fit leads sitting there for three days. The webhook never fired.
2. Data gets corrupted: Your CRM looks like a crime scene. Half the leads show "Campaign: undefined" and your sales team stops trusting "Last Outreach Date."
3. Exit logic breaks: Prospect books Monday. Your system sends two more demo invites Tuesday. LinkedIn flags your accounts.
The hidden cost? Your revenue engine seizes up:
- Sales ignores CRM alerts
- Marketing questions attribution
- Revenue operations spends all day firefighting inbound requests and broken handoffs
According to Nucleus Research, “marketing automation returns $5.44 for every $1 spent.” But that’s only when it’s implemented reliably. If your signals, data, or exits are broken, you won’t scale ROI, you’ll just burn your money.
You need systems that survive human error and contact with reality. That’s what we’re building today.
Before you scale GTM automation, fix your manual ops
If your basics and manual systems aren’t set up properly, adding automation will NOT save you, it'll create more fires than it puts out.
(Good luck explaining that to your CRO.)
Here's the operator ladder:
- Lock down your triggers. Standardize lifecycle definitions before you automate. If “demo request” means five different things in your CRM, your automations will fire in five different directions.
- Prove handoffs by hand. Walk a lead all the way from SDR to AE without automation. If your team can’t do it cleanly, automation will amplify the mess.
- Clean your pipes first. Audit LinkedIn accounts and sender domains. Cold accounts and burnt domains don’t heal themselves; automation just burns them faster.
- Ship with guardrails, not hope. Every workflow needs a version tag, a rollback plan, and someone on the hook when it breaks. Tools can help enforce this. For instance, in HeyReach Workspaces SDRs run on assigned seats, RevOps controls edits, and managers get Master View oversight.
No seat collisions, no conflicting changes.
Once your scaffolding is solid, you can start layering real automation on top.
How to build Go-to-Market automation foundations
Get your core wiring right, first. You'll need two things: a canonical list of what triggers your automation, and iron-clad rules for automating workflows between systems across your GTM ecosystem.
Otherwise, data silos will turn your automation into a game of telephone, where every message gets more and more corrupted.
Assign ownership to lifecycle triggers with signal catalogs
Every lifecycle event needs an owner and a deadline or your qualified leads will rot because "nobody knew whose job it was."
For example, Clay finishes enriching. Then what? Demo gets booked. What follow-up happens next?
Core signals every GTM strategy team needs:
These five lifecycle signals drive your pipeline: enrichment finished, demo no-show, meeting booked, closed-lost, opt-out. For each signal, write down who owns it, how long they have before it goes stale, and what action must fire.
Store this signal catalog in a central ops doc or workspace, so everyone sees the same source of truth and nobody’s left guessing.
Without it, triggers will fire into the void.
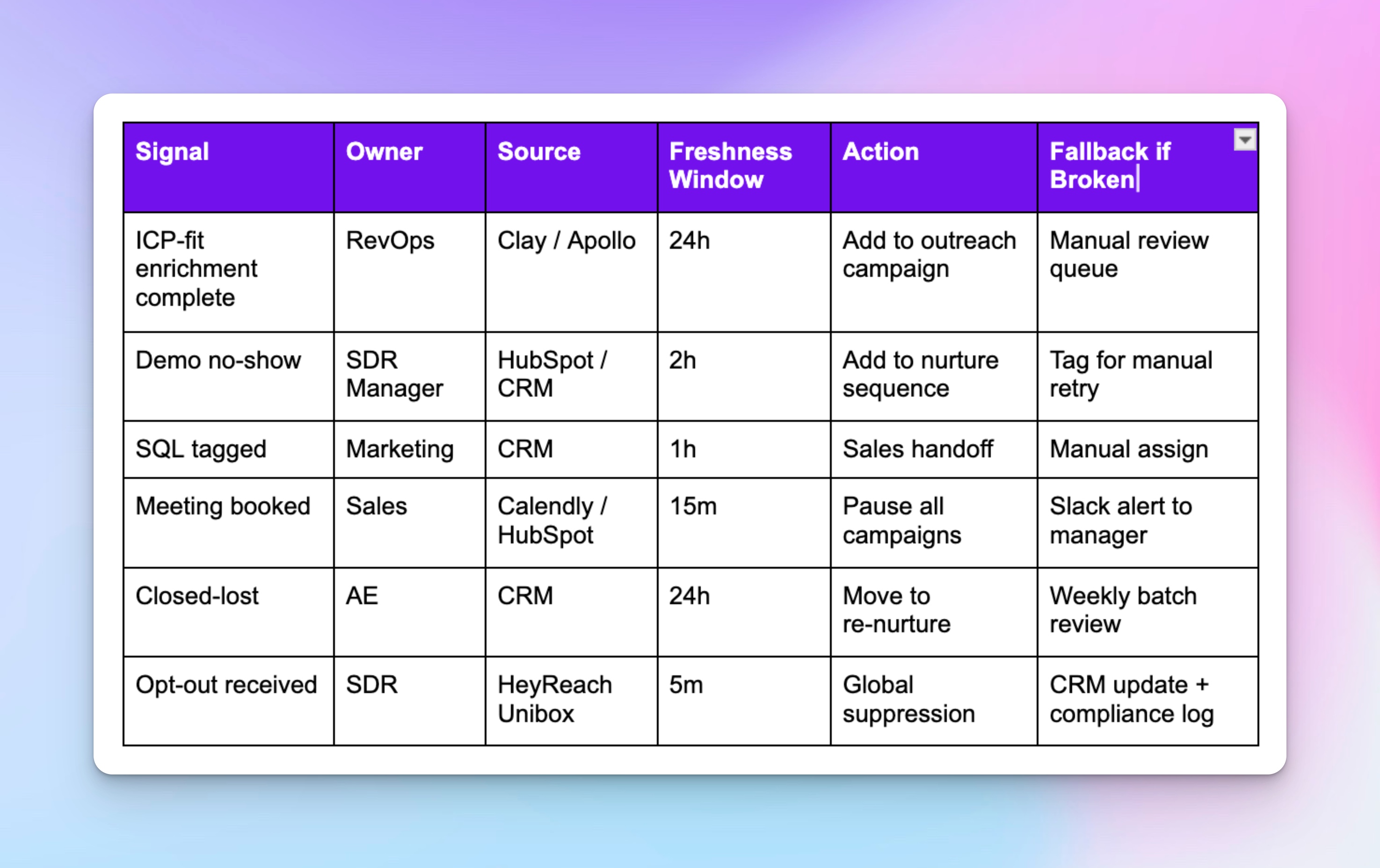
How to build your signal catalog:
Every signal needs three things:
- Ownership → name who’s in charge (the person, not just the role).
- A deadline → set it as a specific freshness window (e.g., “24h” for enrichment).
- Wired actions → connect the signal to an automation (webhook/API) and define a fallback if it fails.
Smart teams take this further by cleaning data at inception.
For example, Barbara Pawar Head of US Sales at Avanade, uses AI as a hygiene copilot to clean notes, stages, and activities at capture. It's basically quality control for your automation triggers.
Your execution layer should then expose these signals reliably: message sent, reply received, connection accepted, campaign completed.
HeyReach, for example, gives you exactly these four signals; no 'engagement score' or 'intent detected' fairy tales. Only facts you can verify.
And if you’re layering AI agents into your tech stack, integrate HeyReach MCP with Claude MCP to get real-time natural language access to the same campaign data you’d pull via API.
Instead of digging through docs, you can just ask Claude: “Which campaigns haven’t started in the last 24h?” Same data, less friction.
You’re welcome! 😉
Prevent pipeline clutter and broken reporting using data contracts
Lock down your critical fields by giving each one a single source of truth, a validation rule, and a clear list of systems that depend on it.
Nothing clogs a pipeline faster than inconsistent fields. If campaign IDs don’t match across systems, or if reply statuses are left blank, your reporting turns into guesswork and weak decision-making, and your automation misfires.
Non-negotiables for GTM outbound automation:
- Campaign ID → must map to a live campaign.
- Sender ID → must tie to a valid seat.
- Reply status → one clean enum (positive/negative / neutral/unclassified).
- Handoff owner → must be a real user ID in your CRM.
- Exit reason → booked, closed_lost, opted_out, churn — nothing else.
- LinkedIn URL → must be a valid profile link.
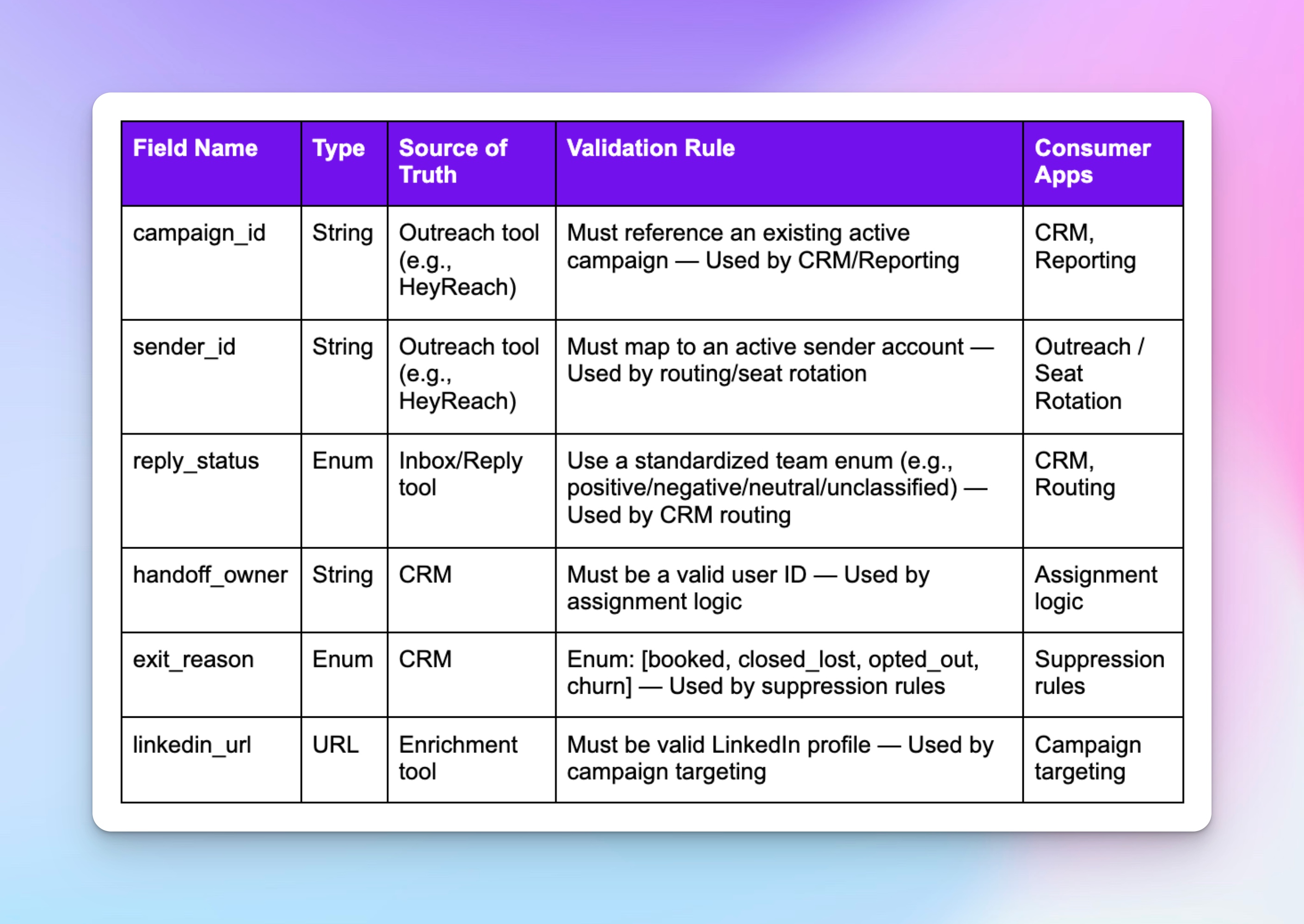
How to build your data contracts:
- Write down the one system that owns each field (your source of truth).
- Set clear validation rules so bad inputs can’t sneak in.
- List the downstream systems that depend on it, so everyone knows what breaks if the field breaks.
Data engineers solved this problem years ago with contracts that stop bad inputs from polluting downstream systems. Companies like Monte Carlo even turned them into code-level guardrails.
The same principle applies in GTM strategy: if campaign_id or reply_status breaks, your pipeline fills with ghosts. Your outreach tools should ensure this doesn't happen.
In HeyReach, Campaign ID isn't optional; you need it to run campaigns. Sender IDs are locked to seat assignments. That's how they prevent the reply routing disasters that tank other setups.
👉 To make this easier, we’ve bundled a ready-to-use Signal Catalog Template and a Data Contracts Template you can drop straight into your ops doc.
4 Plug and Play automation systems for scalable GTM automation systems
Each one solves a specific failure point. Implement them independently or stack them together; just get your automation started.
Lifecycle sync: Turn signals into automated GTM actions
The problem: A lead scored at 9:01 should be in outreach by 9:02. If it takes a week, you’ve already lost. The manual gap between ‘signal fired’ and ‘action taken’ kills more deals than bad copy ever will.
The fix? Stop waiting. Sync lifecycle signals in minutes, not days.
The real killer isn’t enrichment quality; it’s handoff latency. Teams that respond within 60 seconds see nearly 400% more conversions, according to Qwilr.
Event-driven triggers → Outreach campaign start → Fallback queue if data incomplete.
This is speed with guardrails, not sloppy automation.
Lifecycle Sync Runbook
Close the gap between a signal firing and the next action. Each signal is captured, validated, and routed. If the data checks out, the action fires instantly. If not, it drops into a fallback queue so ops can review without losing momentum.

How lifecycle sync runbook works in practice
- Signal captured: a lifecycle event fires (ICP-fit, demo no-show, job change).
- Validation applied: system checks required fields (LinkedIn URL, score, status).
- Action triggered: if valid, the lead is added to the right campaign immediately.
- Fallback queued:if incomplete, it goes into a review queue, so ops can resolve it without losing the lead.
- Execution handled: your outreach platform delivers safely (seat rotation, pacing, scheduling).
Your orchestration layer (automation platforms like Make, Zapier, n8n) decides where leads should go. Your outreach platform executes safely. In HeyReach, that means campaign triggers, account rotation, and pacing guardrails all locked in, so ops doesn’t have to babysit.
👉 Wire this faster, we’ve put together a Lifecycle Sync Template you can plug straight into your orchestration doc.
Speed gets you halfway. But speed without control is just another way to break trust. Which brings us to exits…
Clean exits: Automating campaign pause/stop to protect deliverability
The problem: A prospect books a demo on Monday and on Tuesday, gets two more demo invites, they think you’re sloppy, and that burns trust and your domain in one shot.
That’s a silent exit failure: one missed stop event, and the whole machine keeps pushing, derailing your sales process.
The fix: Exit triggers should fire across systems and pause campaigns instantly, with an audit trail to prove it. Clean exits protect trust, shorten the sales cycle, and save your domain from reputation damage.
Exit triggers → Campaign pause → Evidence logged → Slack alert
Clean exits matrix
When someone books, buys, opts out, or closes, campaigns must stop instantly. The matrix wires this in: the source that detects the exit, the action your outreach tool enforces, the tag or archive for the conversation, and a fallback if anything slips.

How clean exits matrix works in practice
- CRM, calendar, or reply tool flags an event (booked, closed, unsubscribed).
- Your orchestration layer (Zapier, Make, n8n) catches it and calls your outreach platform.
- Your outreach platform enforces the stop: campaigns are paused, conversations are tagged, and history is preserved.
- Slack (or another alert channel) confirms the exit so nobody's guessing.
Automation comes from your orchestration layer firing the right trigger; your outreach platform, like HeyReach, enforces the stop and gives you visibility once that trigger lands. You can pause or resume campaigns on demand, tag conversations in Unibox, and keep full history as your audit trail.
That’s your clean exit path, and the evidence to prove it.
And if you’re layering AI into ops, MCP adds another safety net: it exposes the same conversation and campaign data through a shared standard, so AI tools can troubleshoot exits without messy API builds.
But even with AI, don’t rely on a single source of truth. Most teams miss exit events because they only monitor one system. The pros build detection across CRM, calendar, and reply monitoring. Better to pause twice than miss once.
👉 We’ve mapped a Clean Exits Matrix you can adapt directly into your playbook so exits never get missed.
Observability & reliability: Automating GTM monitoring
The problem: Some of the most dangerous failures don’t make a peep. A webhook drops, retries never fire, exits go unprocessed, and nobody notices because your QBR dashboard is still painting a fairytale of healthy pipeline numbers.
The fix? Reliability engineering + observability; built before you need it. Define your KPI thresholds so alerts mean action.
Retries → Idempotency → Dead-letter queue → Dashboards + alerts.
Observability & Reliability Dashboard Spec
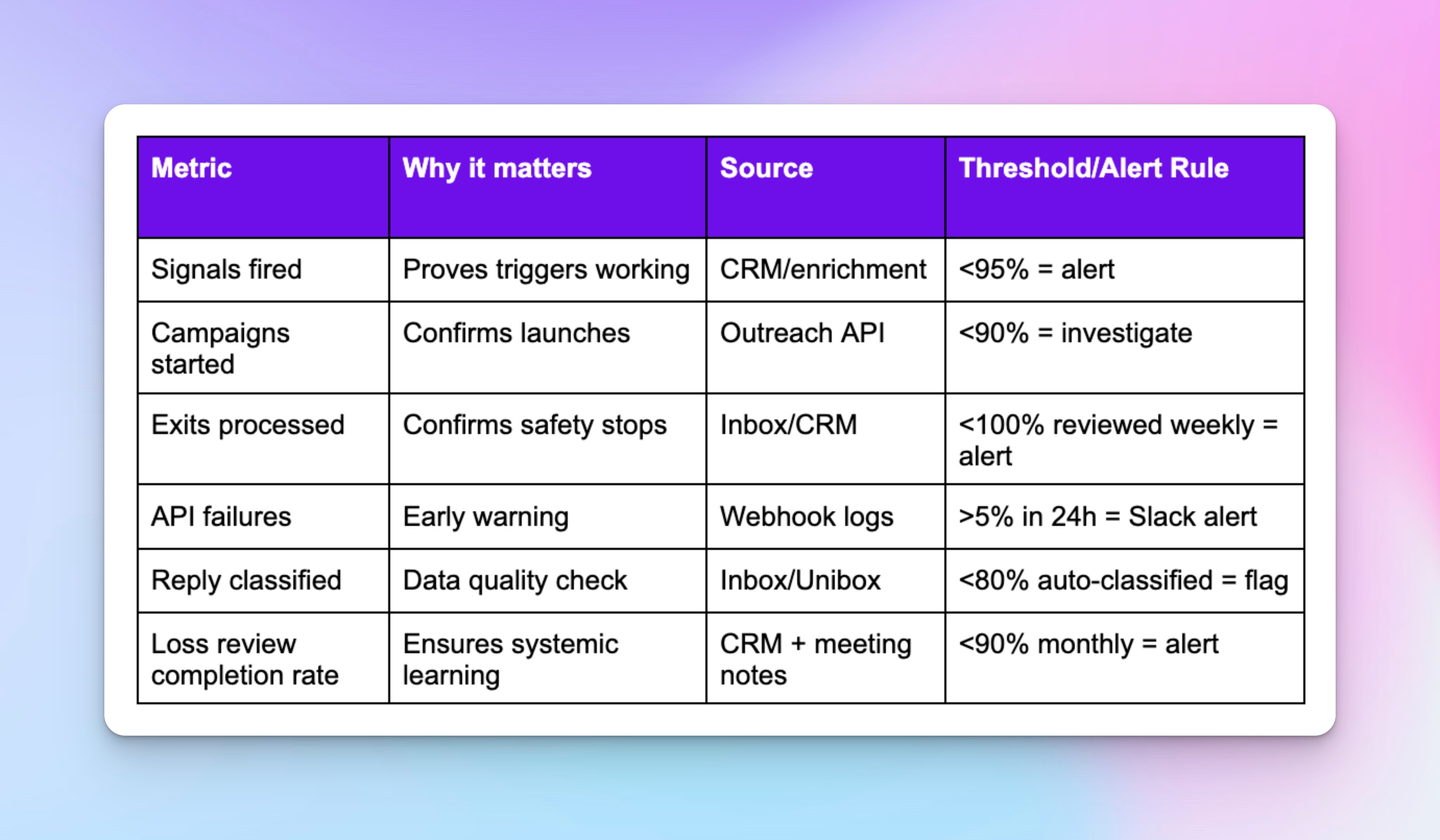
What to monitor daily:
- Signals fired → proves triggers are working.
- Campaigns started → confirms launches actually happen.
- Exits processed → makes sure stop rules fire.
- API failures → early warning before reps notice.
- Reply classified → data quality stays usable.
- Loss review completion → closes the loop on learning.
How to build reliability:
- Every webhook uses an idempotency key (prevent double-triggers).
- All retries implement exponential backoff.
- Dead-letter queue captures failed messages.
- Slack notifications fire on DLQ events.
- Weekly: audit retry success + DLQ counts.
- Monthly: test end-to-end signal flow.
- Anomaly alerts: watch patterns, not just errors (drop in exits, spike in DLQs).
How this works in practice
- Morning dashboard check: RevOps opens the 5-minute health dashboard and sees “Signals fired: 94%.”
- Triage begins: Slack alert shows webhook failures, pointing to a specific integration.
- Root cause: Dead-letter queue reveals rate limiting during peak hours.
- Fix implemented: Add exponential backoff, issue resolved.
- Weekly audit: Review retry success rates and DLQ counts for continuous improvement.
Failures shout; anomalies whisper. The best operators train their systems to catch both!
Slack fires the alert. When someone asks, “Did it actually stop?” your outreach platform should make the answer obvious. HeyReach, for example, provides direct exit tracing through campaign logs and proof in one place, no detective work needed.

Pro tip: Build your observability before you need it. Missed exits quietly inflate customer acquisition costs. When things break at scale, you won't have time to add monitoring.
👉 Missed exits and failed webhooks rarely shout. Make them visible with this Observability Dashboard
- Experimentation & versioning: Test without chaos
The problem: “Ship and pray” campaign tweaks straight into production; no rollback plan, no guardrails, no evidence trail. Once volume scales, one bad test can tank your domain reputation or corrupt reporting across the board.
The fix? Treat experiments like software releases. Every change gets a version, guardrail, and rollback path.
Versioning lets you streamline testing without torpedoing live campaigns.
Version ID → Guardrail → Rollback trigger → Evidence log.
Experimentation/Versioning Spec
Each test logs five essentials: the version tag, what’s changing, the guardrail that caps risk, the rollback trigger if it fails, and the evidence log so you can learn from it.

How this works in practice
- Version launch: Create "Campaign A v1.2" with clear test parameters
- Guardrails activate: System caps test to 10% of audience, sets unsubscribe threshold
- Parallel testing: v1.2 runs alongside v1.1, tracked separately
- Monitoring catches issues: Rollback triggers if metrics breach thresholds
- Evidence preserved: All interactions logged for post-test analysis and learning
For safe testing you need campaign isolation and results tracking. HeyReach handles this through campaign cloning and integrated dashboard monitoring, so evidence isn't scattered across multiple tools.
You see exactly which messages landed, how prospects reacted, and whether the test earned a permanent rollout.
👉 Use our Experimentation Log Template to version safely, add guardrails, and roll back without guesswork.
What happens to your automation stack without systematic governance?
It breaks three different ways by Thursday, and everyone points fingers.
Every workflow needs three things: a version tag, a fallback path, and someone who owns it when it breaks. Without that, misfires multiply.
RevOps tweaks the signal catalog, marketing changes campaign triggers, sales updates handoff logic, and customer success teams shift priorities.
Nobody tells anyone. Ops only discovers the fallout a week later.
Change control basics
Lock down who can change what and who owns enablement.
- Signal catalog → RevOps owns edits, weekly reviews
- Data contracts → Data team owns, RevOps approves, quarterly reviews
- Campaigns → Owner decides, manager approves, version testing before rollout
- Integrations → DevOps owns, 48h notice to everyone
To keep systems reliable, you also need to regularly audit what went wrong.
Monthly loss review
The fastest way to catch automation failures is to trace backwards from deals you lost.
- RevOps + Sales pick one recent closed-lost.
- Follow it back through routing, exits, and handoffs, and the customer journey.
- Log one fix to specific team members with a deadline.
- Re-check next month. This cadence builds feedback loops that harden the system
Pro tip: Signal-based pods
Instead of organizing my function, many teams are shifting to pods organized by trigger (e.g., demo-booked pod, churn-risk pod). Ownership follows the signal, not the org chart.
Structure beats speed when reliability matters.
Next steps: Stop the bleeding first
Let’s be real, when you're in crisis mode (leads not getting contacted, prospects getting messaged after booking meetings, webhooks failing), you can't afford to spend weeks methodically building the full Blueprint Pack.
You need to stop the immediate damage first.
Week 1 – Emergency fixes
- Audit exits: Pull your last 50 “meeting booked” contacts. If campaigns are still hitting them, stop everything. That’s not nurture, that’s malpractice.
- Test triggers: Hit every webhook URL yourself. If curl throws errors, guess what — your leads never fired either.
- Lock your fields: campaign_id and sender_id aren’t “nice to haves.” If they’re blank, your reporting is fiction and your routing is roulette.
Week 2 – Stabilize
- Wire one exit trigger: Meeting booked → pause all campaigns. No excuses. Miss one exit and you torch your sender reputation.
- Add alerts: Webhooks fail silently. Slack shouldn’t. If you’re not getting pinged when something breaks, you’re flying blind.
- Pick a system: Download the Blueprint Pack. Choose one from these automation playbook. Build it end to end. Don’t duct-tape three at once.
Month 2 – Scale safely
- Layer in the rest: Lifecycle Sync, Clean Exits, Observability. Each plugs a different leak.
- Run weekly health checks: Signals fired, exits processed, campaigns clean. Don’t wait for QBRs to learn your pipeline’s a ghost town.
- Plan capacity jumps: Decide what breaks at 2x volume:lead flow, SDR headcount, sender limits. Fix it now, not at 11 PM when your CRO asks where the pipeline went.
👉 Stop the bleeding. Then build systems that don’t collapse the moment you push real volume.
Build scalable GTM automation systems that survive contact with reality (not just pretty demos)
You probably think you need more automation tools, but you don’t! What you need is reliability engineering.
Fix your manual ops before you automate: build signal catalogs before leads go cold, wire exit triggers before prospects complain, and add observability before QBRs become post-mortems.
Then layer in automation: workflows that fire signals into the right campaigns, stop when prospects convert, and keep operators out of firefighting mode.
That feeling your automation gave you at 100 leads per month? You can have it at 1,000. At 10,000. And trust me, budget won’t make the difference; reliability engineering will.
Of course, you can keep duct-taping your system and hoping it holds (don’t hold your breath, though.) Build automation that actually scales with your ambitions.
In simple words: Systems scale when they have structure. That means pairing orchestration tools with execution platforms like HeyReach that enforce safety: seat rotation prevents account collisions, conversation tracking maintains context, and campaign controls stop the chaos that breaks other setups.
Engineer for reliability first. Scale second.
✅ We’ve bundled all six blueprints into one Notion workspace, so you can plug them straight into your ops doc when you’re ready to scale
- Signal Catalog Template
- Data Contract Table
- Lifecycle Sync Runbook
- Clean Exits Matrix
- Observability Dashboard Spec
- Reliability Engineering Checklist
Get the bundle - Start scaling your outreach with HeyReach today.

Send your first LinkedIn campaign in HeyReach for free - no card required